Back
[00:33:32] <CIA-19> 03jepler 07v2_1_branch * 10emc2/debian/control.in: without yapps2-runtime, the emc-dev package does not work
[00:34:30] <CIA-19> 03jepler 07v2_1_branch * 10emc2/debian/changelog: note bugfix
[01:31:50] <CIA-19> 03jmkasunich 07TRUNK * 10infrastructure/farm-scripts/ (build emc2_build emc2_build_sim): only do a complete build (make clean; make) if its been at least 12 hours since the last complete build
[02:11:28] <CIA-19> 03jmkasunich 07TRUNK * 10infrastructure/farm-scripts/ (build emc2_build emc2_build_sim): redo complete/incremental build stuff
[02:43:45] <CIA-19> 03compile-farm 07Ubuntu 5.10 (breezy) realtime (2.6.12-magma) * 10emc2head/: build PASSED
[02:52:44] <jmkasunich> stepper abuse: zero to 775 RPM and back down to zero in 100mS (precisely one complete rev), then wait 20mS and repeat going the other way......
[02:53:41] <jmkasunich> accel and decel rates are 500 rev/sec^2 (30000RPM/second)
[02:53:49] <cradek> it's working right now?
[02:54:20] <jmkasunich> no, its losing a step every once in a while
[02:54:28] <jmkasunich> I'm abusing it to try to hunt down the problem
[02:54:33] <CIA-19> 03cradek 07TRUNK * 10emc2/docs/man/man9/.cvsignore: new manpages
[02:54:35] <jmkasunich> I think its setup/hold maybe
[02:56:39] <jmkasunich> its _not_ the motor getting out of sync with the drive
[02:56:54] <jmkasunich> its the drive getting out of sync with the commanded steps
[02:57:23] <cradek> I thought the geckos didn't require fancy timing considerations
[02:57:41] <jmkasunich> it depends on who you ask, and which geckos
[02:58:00] <jmkasunich> the new G203's have a cpld, and I think they have very simple timing requirements
[02:58:06] <jmkasunich> the older ones aren't so nice
[02:58:23] <jmkasunich> and the ones with pulse multipliers (which I don't have) are really nasty
[02:59:24] <Skullworks> And which are you using?
[02:59:38] <jmkasunich> G202, version 13 (about a year and a half old)
[03:01:50] <Skullworks> I figured if I was going to pay the price of a gecko, I'd go full servo. But I do have a HCNC set I'm going to try on my X3 just for giggles.
[03:05:01] <CIA-19> 03cradek 07TRUNK * 10emc2/src/emc/rs274ngc/interp_convert.cc: fix angled entry and exit for canned threading cycle
[03:05:01] <CIA-19> 03cradek 07TRUNK * 10emc2/nc_files/g76.ngc: fix angled entry and exit for canned threading cycle
[03:06:34] <cradek> are all the servo gecko drives also step/dir?
[03:06:40] <jmkasunich> yes
[03:06:41] <jepler> cradek: yes, that's my impression anyway
[03:06:52] <jepler> cradek: reportedly you can sabotage the thing into a 0..5V-input analog servo
[03:06:56] <jmkasunich> although they are probably more immune to siming issues
[03:07:11] <jmkasunich> the step/dir inputs simply drive an up down counter chip on the servo drives
[03:07:27] <jmkasunich> the counter is compared to another counter driven by the encoder, to generate an error signal
[03:07:28] <cradek> too bad he doesn't make one with an analog input
[03:07:45] <jmkasunich> actually he has posted a hack to let you drive it with analog
[03:07:55] <Skullworks> yes but the sync lock is +/- 128 ecoder counts
[03:07:57] <jmkasunich> don't recall the details
[03:08:05] <cradek> didn't abort (esc) turn off the spindle in the past?
[03:08:08] <jepler> seems like elson's PWM servo drives are a better choice if you want to close the loop on the PC
[03:08:31] <jmkasunich> jepler: yeah, step/dir servo drives seem like a kuldge to me
[03:08:45] <jmkasunich> they're targeted at software that can't do real servo
[03:08:58] <cradek> yeah I'd probably go with elson's stuff which targets emc
[03:09:29] <Skullworks> plus jon's units have much higher Volt/amp capacity
[03:10:01] <cradek> maybe someday I'll have a mill that requires me to worry about that
[03:10:11] <cradek> jepler: do you still have a running emc1?
[03:10:27] <jepler> cradek: I have an emc sim at work, that's it
[03:10:39] <cradek> let me try 2.0 first
[03:11:43] <cradek> yeah I think we have a regression - in 2.0.5 the spindle turns off (and brake on) at abort
[03:12:08] <jmkasunich> regression or intentional change?
[03:12:32] <cradek> I think I would have remembered (and argued) if it was intentional
[03:12:44] <cradek> this was also broken (way) before 2.0 iirc
[03:13:16] <jmkasunich> if you turn the spindle off at the same time as you start decelling the axes, and the cut is heavy/spindle inertia is low, compared to axis decel, you might find yourself driving an axis against a stopped cutter (which breaks the cutter)
[03:13:43] <cradek> pick your poison
[03:13:48] <jmkasunich> yeah
[03:14:15] <jmkasunich> does the spec say what abort is supposed to do?
[03:14:30] <cradek> no, I think it says exactly nothing about abort
[03:17:28] <CIA-19> 03jmkasunich 07TRUNK * 10emc2/src/hal/utils/ (scope_disp.c scope_trig.c): calculate and display correct trigger level when used with offset
[03:17:41] <cradek> hmm, the spindle also used to turn off when switching between auto and mdi modes (which I always hated), and it doesn't do that now either
[03:21:21] <CIA-19> 03jmkasunich 07v2_1_branch * 10emc2/src/hal/utils/ (scope_disp.c scope_trig.c): backport bugfix: calculate and display correct trigger level when used with offset
[03:24:00] <jmkasunich> what is the significance of the "load average" numbers from uptime?
[03:24:09] <jmkasunich> are they just some arbitrary scale?
[03:24:19] <cradek> 1.0 = full processor utilization by one process
[03:24:44] <jmkasunich> so this is pretty busy?
[03:24:45] <jmkasunich> 22:22:53 up 28 days, 4:29, 6 users, load average: 10.06, 9.54, 9.28
[03:25:11] <cradek> yeah 10 is pretty high.
[03:26:38] <jmkasunich> thats with two of the farm vm's suspended
[03:29:30] <cradek> the plot thickens
[03:29:40] <jmkasunich> the abort/spindle plot?
[03:29:45] <cradek> coolants still turn off when switching modes or aborting
[03:29:59] <cradek> so this broke when we moved spindle control from iocontrol to motion
[03:30:09] <jmkasunich> I was just gonna say that
[03:30:32] <cradek> 2.1.1 here we come
[03:30:52] <cradek> wish alex were here
[03:30:56] <cradek> was
[03:37:23] <jepler> "load" may reflect processes waiting on disk, too. for instance, my reported load is higher while running a bunch of disk-intensive "find"s, even though user+system is at most 20%
[03:38:33] <jepler> the three numbers represent moving averages with different weights
[03:41:35] <jmkasunich> yeah, 1, 5, and 15 minutes
[03:41:55] <jmkasunich> thats in the manpage, but exactly what kind of "load" the numbers represent isn't
[03:42:10] <jmkasunich> is there a straightforward way to get user+sysem?
[03:42:19] <jmkasunich> looking at top is the only way I know
[03:42:56] <jepler> "vmstat 5" will show you those numbers too
[03:43:16] <jepler> I think the information is in /proc/stat but not in an easy-to-read format
[03:44:20] <jmkasunich> I was thinking of having the farm slots check load each time they wake up, and if the load is high, go back to sleep for another 5 mins
[03:44:46] <jmkasunich> except I just realized that checking a VM's load doesn't tell you how busy the host is
[03:55:09] <CIA-19> 03cradek 07TRUNK * 10emc2/src/emc/task/taskintf.cc: fix bug that left the spindle on after abort
[03:58:43] <CIA-19> 03cradek 07v2_1_branch * 10emc2/src/emc/task/taskintf.cc: backport 1.62: fix bug that left the spindle on after abort
[04:02:39] <CIA-19> 03cradek 07v2_1_branch * 10emc2/debian/changelog: fix
[04:03:02] <jepler> more arc fitting stuff:
http://axis.unpy.net/index.cgi/01171767993
[04:05:15] <jmkasunich> heh - another case where the small pic is bigger than the original
[04:05:20] <jepler> There are enough letters to specify one full bezier curve on a single line: G? P- Q- I- J- X- Y- Z-
[04:06:03] <cradek> PQ and IJ are the control points (relative to the start?)?
[04:06:08] <jepler> something like that
[04:06:18] <cradek> what's Z?
[04:06:26] <cradek> I mean, how does Z work
[04:06:30] <jepler> and if Z specifies motion, it is linear, a "helical spline"
[04:07:08] <jepler> if the total curve length is L and the distance so far is M, then you're at oldz + (Z-oldz) * (M/L)
[04:07:23] <cradek> got it
[04:07:35] <cradek> and we can do that with just the existing helixes
[04:07:38] <jepler> (in the emc implementation, L is the sum of the length of the arcs used to fit the spline)
[04:07:43] <cradek> right
[04:08:01] <cradek> cool, I say stick it in there
[04:08:26] <jepler> I will, just not tonight
[04:08:31] <cradek> neat
[04:09:12] <cradek> will you just make a SPLINE canon call and do this in task?
[04:09:23] <jmkasunich> load average: 14.66, 13.69, 11.76 :-(
[04:10:09] <jepler> cradek: I think so, though I'm now realizing that makes things harder in AXIS
[04:10:09] <cradek> if so, task knows the tolerance so you could do something smart based on that (interp doesn't know anything about that)
[04:10:25] <jmkasunich> these "splines" are constrained to be in a particular plane (disregarding the linear Z), right?
[04:10:54] <jmkasunich> a general spline would not be, and we should make sure the g-code can be extended to the general case if we ever figure out how to do that
[04:11:25] <jepler> there are still enough floating-point numbers: P- Q- R- I- J- K- X- Y- Z-
[04:11:47] <jepler> I don't think the biarc method works when the curve is not planar, though.
[04:12:11] <jmkasunich> I didn't think it would
[04:12:24] <jmkasunich> I was thinking of someday having a real spline primitive in the TP
[04:12:28] <jepler> (even assuming non-planar arcs)
[04:13:00] <jmkasunich> (someday being after somebody solves the "where am I on the spline" problem)
[04:15:47] <cradek> I bet soft limits don't actually work right for arcs (only the endpoint is tested)
[04:18:04] <jepler> I remember noticing that too, then looking the other way
[04:18:16] <jepler> "AXIS will probably catch it"
[04:19:43] <cradek> yuck
[04:21:07] <crepincdotcom> ^^ found that out the other day
[04:21:21] <cradek> really? you ran into it?
[04:21:53] <crepincdotcom> quite literally. i did and arc and i ran the table into the mill
[04:21:56] <crepincdotcom> *an arc
[04:22:10] <cradek> did you have soft limits that should have protected you?
[04:22:45] <crepincdotcom> yes
[04:23:00] <crepincdotcom> well i asume so, theyve worked in the past
[04:24:46] <cradek> did you do the arc in MDI?
[04:25:30] <crepincdotcom> yes, just went to do a big circle for fun
[04:26:00] <cradek> ok, I just confirmed it here too
[04:26:04] <crepincdotcom> if i had known this was an axis issue i would have taken screen shots for you
[04:26:10] <crepincdotcom> i thought i had just done soemthing stupid
[04:26:33] <cradek> it's not an axis issue, it's a motion controller issue
[04:26:36] <cradek> * cradek pokes jmkasunich
[04:26:42] <jmkasunich> ow!
[04:26:43] <crepincdotcom> brb
[04:27:23] <cradek> and, I bet, a pain in the neck to get right
[04:28:14] <jepler> added a graph of the velocity profile while following the fitted splines:
http://axis.unpy.net/01171767993 -- is there a "first or last segment" blending bug? I wonder why those notches are there.
[04:28:34] <jepler> http://axis.unpy.net/files/01171767993/spline-velocity-profile.png
[04:29:48] <cradek> about how many arcs is it?
[04:30:17] <jepler> overall the program (3 passes) is 42 lines
[04:30:36] <jepler> 4, 8, and 16 arcs per circuit
[04:30:47] <cradek> is this the vel profile for the 16?
[04:30:56] <jepler> it's all 3, back to back
[04:31:02] <jepler> 4 first
[04:31:25] <cradek> I don't understand what I'm looking at then
[04:32:50] <jepler> er -- 8, 16, and 32 arcs per circuit
[04:32:53] <jepler> http://axis.unpy.net/index.cgi-files/01171767993/spline-velocity-profile2.png
[04:32:59] <jepler> here's just one circuit, 8 arcs
[04:33:09] <jepler> they should all be roughly the same length
[04:34:04] <jepler> hm I can see one other tiny notch so it's not after the first segment that the velocity dips so much
[04:34:10] <cradek> I see that too
[04:34:33] <cradek> the blends that are right are very good... but some are wrong
[04:35:16] <jepler> download the python from that blog entry and change the generating lines at the end to:
[04:35:20] <jepler> print "F100"
[04:35:20] <cradek> it doesn't go to 0, so I don't think it's a starvation
[04:35:23] <jepler> spline(P(0,0), P(.25,1), P(1,1), P(2,0), 2)
[04:35:22] <jepler> that's the program I'm running
[04:35:26] <jepler> spline(P(2,0), P(3,-1), P(-.25,-1), P(0,0), 2)
[04:36:04] <jepler> I've also pastebinned the generated file:
http://pastebin.ca/361479
[04:39:31] <jepler> if I make it go around twice (same exact parameters) the notch doesn't happen the second time
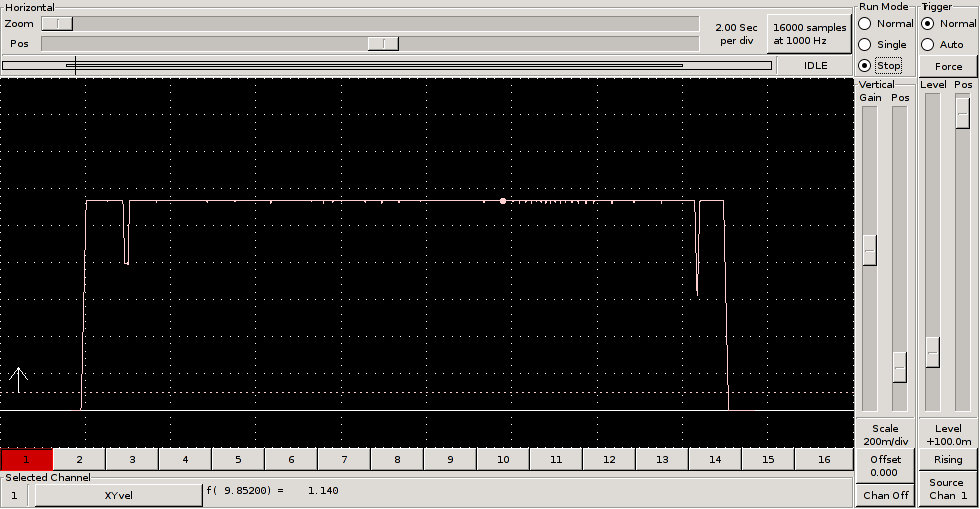
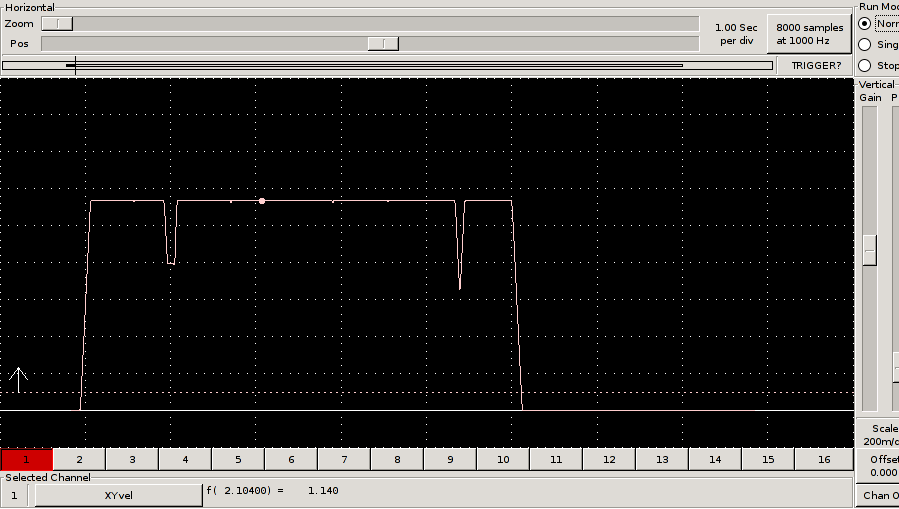
[04:39:51] <cradek> http://timeguy.com/cradek-files/emc/biarcvel.png
[04:40:32] <cradek> some of them are being done at a different velocity?
[04:41:08] <cradek> it would be nice to have the seq nums in halscope...
[04:41:39] <jmkasunich> are they in a global or struct that exists outside the tp?
[04:41:46] <cradek> yes, stat buf
[04:42:21] <jmkasunich> the last part of control.c has some hal params that you can use for debug - just assign the value of what you want to see to one of the params
[04:42:39] <jmkasunich> I bet you want ints tho.... the test params are 2 bit and 2 float
[04:42:47] <jmkasunich> not hard to add a couple s32
[04:43:37] <jmkasunich> line 2377 in control.c
[04:44:06] <jmkasunich> you want me to add a couple s32 ones?
[04:44:36] <cradek> that would be great - let me try to figure out what the field to use is
[04:44:48] <jmkasunich> ok
[04:44:49] <jepler> http://emergent.unpy.net/index.cgi-files/sandbox/lines-velocity-profile2.png
[04:44:55] <jepler> this is just 'G1 X.4 / G1 X.8 ...'
[04:45:01] <jepler> it should also be a real easy case for the planner
[04:46:30] <jepler> 6 .4" movements in all
[04:47:09] <cradek> I bet we're seeing accel mismatches because of the non-tangent end
[04:47:22] <jepler> in the case of the lines only in X?
[04:47:58] <cradek> I don't understand your plot again
[04:48:43] <jepler> that's running this program:
http://pastebin.ca/361490
[04:48:52] <jepler> it's just movements towards +X, each .4" long
[04:49:03] <jepler> then back to the origin -- I assume that's the actual stop
[04:52:10] <jepler> goodnight
[04:53:20] <cradek> goodnight
[04:53:57] <jmkasunich> goodnight jeff
[04:55:09] <CIA-19> 03jmkasunich 07TRUNK * 10emc2/src/emc/motion/ (control.c mot_priv.h motion.c): added s32 debug params to motion controller
[04:55:12] <jmkasunich> there you go...
[04:55:28] <jmkasunich> right now, number 1 is connected to the X axis homing state (state machine)
[04:55:31] <jmkasunich> just for testing
[04:55:39] <jmkasunich> you can connect either one or both to whatever you need
[04:55:55] <jmkasunich> number 0 is just set to 0 right now
[04:56:10] <cradek> thanks, let me try it
[04:59:23] <cradek> neat
[04:59:26] <cradek> works like a charm
[05:00:20] <CIA-19> 03cradek 07TRUNK * 10emc2/src/emc/motion/control.c: give current motion id to halscope
[05:03:50] <cradek> http://timeguy.com/cradek-files/emc/biarcvel.png
[05:05:14] <jmkasunich> pretty....
[05:05:22] <jmkasunich> but I hope its more enlightening to you than it is to me
[05:05:34] <cradek> no, I especially don't understand the first dip
[05:09:18] <jmkasunich> you can use the other debug pins to get a look at TP internals
[05:11:05] <cradek> yuck, the TRAJ_CIRCULAR_MOVE debug output is bogus
[05:21:08] <CIA-19> 03cradek 07TRUNK * 10emc2/src/emc/nml_intf/emc.cc: fix circular move traj issue debug output
[05:26:02] <CIA-19> 03jmkasunich 07TRUNK * 10emc2/docs/man/man9/ (sampler.9 streamer.9): add enable pins to streamer and sampler
[05:26:03] <CIA-19> 03jmkasunich 07TRUNK * 10emc2/src/hal/components/ (sampler.c sampler_usr.c streamer.c streamer_usr.c): add enable pins to streamer and sampler
[05:31:30] <cradek> well I fixed a task thing and an nml thing - I think it's time for bed
[05:31:36] <jmkasunich> ;-)
[08:45:16] <K`zan> Nigth all
[13:14:31] <alex_joni> morning all
[14:29:06] <awallin> what's up?
[14:35:15] <CIA-19> 03jepler 07TRUNK * 10emc2/debian/control.in: got import error when running comp if yapps2-runtime is not installed
[14:36:10] <CIA-19> 03jepler 07TRUNK * 10emc2/src/Makefile: make installation dirs at the right time during the build, otherwise 'install-python' fails when making the deb
[14:37:34] <jepler> eek
[14:37:48] <jepler> * jepler imagines bezier curve + tool shape compensation
[14:47:47] <awallin> jepler: is someone doing bezier curves for the interp now?
[14:53:37] <jepler> awallin: right now I'm looking at the difficulty of adding it to the interpreter
[14:55:17] <awallin> jepler: would the interpreter convert a bezier curve to canon-commands(lines and arcs)?, or would the trajectory controller be taught a new type of move (bezier)
[14:57:03] <jepler> awallin: the interpreter would have a canon call for "cubic bezier curve", but the initial implementation would be to convert that curve into a series of arcs before the motion reaches the real-time code.
http://axis.unpy.net/01171767993
[16:08:13] <jepler> http://emergent.unpy.net/index.cgi-files/sandbox/emc2-g5-spline.png
[16:09:48] <alex_joni> cool
[16:11:03] <jepler> right now both axis and emc interpolate it with a fixed number of lines (10) but the next step is to use the biarc algorithm in emc
[16:13:04] <jepler> actually the next step is apparently to make chocolate chip cookies
[16:14:10] <tomp> bi-chip
[16:15:41] <alex_joni> bichocolate chips
[16:15:51] <tomp> ;)
[16:20:52] <DavidMB> Anyone have experiance with EMC2 & standard stepper config - and able to spare a little time to help?
[16:21:46] <alex_joni> DavidMB: go ahead, there might be people around with helpfull info
[16:28:08] <DavidMB> Ok, I have a setup that works fine with EMC1 ( 4.51 I think ), I use bridgeportio to generate a spindle on signal to control on-off spindle, this is all working fine. Have installed Ubuntu/EMC2 on a second hard disk and motion seems to work ok apart from some fiddling with scales etc, but I can't get the spindle to come on. Have two paraports working fine, even switched load order and run step & direction through second car
[16:29:02] <alex_joni> what Ubuntu/EMC2 disk did you use?
[16:29:15] <alex_joni> I mean how old is it (I'm interested in the emc2 version on it)
[16:29:43] <DavidMB> I think it's 6.06, the ISO image from the LinuxCNC site.
[16:29:53] <alex_joni> ok, did you get that lately?
[16:30:33] <alex_joni> DavidMB: if it's 1-2months old then it's probably emc2-2.0.x
[16:30:42] <alex_joni> if it's newer then it's emc2-2.1.0
[16:30:50] <DavidMB> Yes sorry, it was downloaded last week.
[16:30:58] <alex_joni> I only ask because the spindle control has been changed in 2.1.0
[16:31:06] <alex_joni> ok.. good
[16:31:07] <DavidMB> Sure it's 2.1.0
[16:31:13] <alex_joni> do you know about HAL?
[16:31:25] <DavidMB> Just learing,
[16:31:31] <alex_joni> I read that you were able to run step & dir on the second card
[16:31:36] <DavidMB> learning.
[16:31:42] <alex_joni> that means at least some parts you surely know already :)
[16:31:51] <DavidMB> Yes thats correct
[16:32:06] <alex_joni> ok.. you had the spindle driven by a on/off pin ?
[16:32:25] <DavidMB> Yes I drive an opto isolated relay.
[16:33:49] <alex_joni> ok, looking at the default config I see there is some part that refers to spindle control
[16:34:01] <alex_joni> # create a signal for "spindle on"
[16:34:01] <alex_joni> newsig spindle-on bit
[16:34:01] <alex_joni> # connect the controller to it
[16:34:01] <alex_joni> linkps motion.spindle-on => spindle-on
[16:34:01] <alex_joni> # connect it to a physical pin
[16:34:04] <alex_joni> linksp spindle-on => parport.0.pin-09-out
[16:34:45] <DavidMB> Yes I changed it to use pin 3 and then pin 5 with no joy.
[16:34:57] <alex_joni> are you sure those are output pins?
[16:35:05] <alex_joni> 3 and 5 are usually inputs
[16:35:33] <alex_joni> unless you define the port as output, 3 and 5 are actually DATA2 and DATA4 (which are bidir, and by default outputs)
[16:36:30] <DavidMB> will check, but doc says parports config for out unless specified for in
[16:37:13] <alex_joni> right, default is out
[16:37:21] <alex_joni> not sure what I am thinking :P
[16:37:38] <alex_joni> can you check the level of the parport pin?
[16:38:56] <alex_joni> DavidMB: you seem on the right track.. gotta run for an hour.. but I'll be back
[16:39:05] <alex_joni> in the mean time there might be others helpfull in here
[16:39:23] <DavidMB> yes, I was going to put a proper meter on it next, I think the pin is not outputting the signal, but when I swap the HD and run up EMC1 it works so I guess I'm missing something in config.
[16:59:45] <tomp> alex_joni: I was able to install ubuntu 6.06 by taking the hd out of a very limited system, and using another box, add vmlinz & initrd.gz of .iso img to the hd's /boot. Then edit grub to use those to boot 'NewInstall' with. I put the hd back into laptop & booted. Those 2 files look to the cd for the real filesystem. This let me install from the cd, tho i cant boot from the cd :)
[17:00:53] <tomp> alex_joni: i thought you were experimenting with alternate small linux's and it might be useful
[17:23:44] <alex_joni> tomp: cool, thanks for mentioning that
[17:24:48] <jmkasunich> hi folks
[17:28:43] <ejholmgren> hi
[17:33:19] <alex_joni> hi
[17:33:29] <SWPadnos> hi
[17:34:40] <jepler> drat, it didn't work on the first try:
http://emergent.unpy.net/index.cgi-files/sandbox/wrong-arcs.png
[17:34:51] <lerneaen_hydra> eek
[17:35:06] <SWPadnos> was that supposed to be a hairy egg?
[17:35:12] <lerneaen_hydra> is that a pure bezier?
[17:35:45] <jepler> SWPadnos: no, the backplot should match the preview plot
[17:36:22] <jepler> lerneaen_hydra: define "pure". The user specifies a cubic bezier in the XY plane by giving two control points and an endpoint
[17:36:37] <SWPadnos> err - I hope you changed something to get that plot O_O
[17:37:11] <lerneaen_hydra> ok, so it's a bezier and not straight-line segments, as one could think if only looking at the plot (low-poly-count bezier)
[17:37:42] <jepler> lerneaen_hydra: just like for arcs, AXIS approximates it as a series of lines for the preview plot
[17:37:57] <lerneaen_hydra> what does it base the number on?
[17:38:04] <jepler> base 10
[17:38:06] <lerneaen_hydra> some XX/radian/distance?
[17:39:56] <jepler> lerneaen_hydra: it uses a number of segments that depends on the angle of the arc
[17:39:59] <jepler> from 8 to 128
[17:40:10] <lerneaen_hydra> ah, ok
[18:10:43] <DanielFalck> I have a question about Axis config- how do I change the appearance of the tool in the opengl window? I want to change tools to .5 em and don't know how to get away from the v-bit
[18:11:18] <DanielFalck> I am doing an M6 Txx with a different diameter tool in the program
[18:11:28] <DanielFalck> and have edited sim.tbl to reflect that
[18:11:42] <DanielFalck> with .5 dia tool
[18:12:12] <DanielFalck> do I need to reload axis to make it see it?
[18:14:20] <cradek> did you reload the tool table? (it's on the menu)
[18:15:08] <DanielFalck> ok that's it- thanks
[18:15:17] <cradek> welcome
[18:15:21] <DanielFalck> cool feature
[18:15:47] <DanielFalck> I have been using apt360 to generate a few simple programs - it's very cool too
[18:18:30] <cradek> I saw the new wiki pages about that - but I haven't played with it yet
[18:19:21] <DanielFalck> I have nedit open for editing and set up a shell command to apt360 | vapt and now have Axis and vapt simulating the gcode- I'm very happy : )
[18:20:02] <lerneaen_hydra> DanielFalck; how's apt going?
[18:20:08] <DanielFalck> you should seriously try it out- there are a lot of things that are already done for gcode generation that will blow you away
[18:20:08] <cradek> apt looks like one of those things that you'd be happy to still/again have if you learned it long ago, but maybe doesn't have a lot of attraction for a new user
[18:20:44] <DanielFalck> but for someone like you- who can harness it it's very good
[18:21:28] <jepler> cradek: uh oh -- my still-buggy biarcs code is calling ARC_FEED() to make its motions, but the resulting movements are way out of the velocity limits
[18:21:33] <DanielFalck> Brent is using it at his workplace for some stuff that the commercial cam system can't handle
[18:21:48] <ejholmgren> translation "cradek: expand your ninja powers"
[18:21:48] <DanielFalck> 4th axis continous stuff
[18:22:03] <cradek> jepler: uh-oh, are the arcs bogus somehow and it's not being caught?
[18:22:29] <jepler> cradek: I'm not sure -- they are "nearly lines"
[18:22:50] <cradek> huh
[18:23:16] <jepler> in fact I notice there's a case in ARC_FEED to handle arcs-that-are-lines -- I doubt it's right, because it's never been exercised
[18:23:18] <awallin> large R compared to the length of the arc
[18:23:22] <jepler> http://emergent.unpy.net/index.cgi-files/sandbox/wrong-arcs2.png
[18:23:22] <awallin> ?
[18:23:55] <cradek> haha
[18:24:03] <cradek> doesn't seem quite right
[18:24:05] <jepler> if my debugging statements can be trusted, the radius passed in is fairly small
[18:25:19] <awallin> can you grab the output of your bezier to arc's function, write that in G2/3 statements, and see how that code runs?
[18:26:04] <jepler> I have the earlier, python implementation, and it doesn't do anything this crazy
[18:26:42] <jepler> but the numbers generated by both are a little different (a lurking bug) and the numbers given to ARC_FEED are wildly different from the numbers specified in a G2/G3 so that translation is probably bogus too
[18:28:45] <cradek> btw I fixed the arc traj message's debug, you could compare there
[18:41:13] <skunkworks> jepler: you had mentioned that there was modbus support in the verson that you integrated into emc.. Do you see a reason why it would not work?
[18:42:34] <skunkworks> * skunkworks is talking about classic ladder... sorry
[18:44:19] <jepler> skunkworks: I don't have a clue in the world about modbus
[18:44:50] <jepler> skunkworks: since the classicladder logic portion runs in realtime code, it doesn't have any code to actually send or receive bytes on a serial bus
[18:45:36] <jepler> so I'm pretty sure it can't actually do anything
[18:47:18] <skunkworks> Thanks. I didn't know if it was something within classicladder - (not a clue)
[18:47:44] <jepler> anyway, with HAL it doesn't make sense for classicladder to speak the modbus protocol -- a HAL module should speak modbus and provide appropriate HAL pins.
[18:48:11] <jmkasunich> I agree with jeff
[18:48:16] <skunkworks> http://www.cnczone.com/forums/showthread.php?p=259897#post259897
[18:48:27] <jmkasunich> the CL modbus code might be a good start on such a driver
[18:48:34] <jmkasunich> but it should be pulled out of CL
[18:48:43] <skunkworks> I agree with what ever you guys agree with :)
[18:49:32] <lerman__> lerman__ is now known as lerman
[18:49:34] <jepler> YAY found the bug, now the spline approximation is good
[18:50:00] <SWPadnos> since modbus is serial, and therefore "slow", a userspace serial driver that exports HAL pins should be relatively easy
[18:50:21] <SWPadnos> I thikn we've been thinking about an RT serial driver for HAL, which may not be the best way to go for I/O
[18:50:40] <SWPadnos> (of course, it would be needed for serial motor drivers ... )
[18:53:09] <jmkasunich> the problem with modbus is that the people who want to use it and the people who are able to write the driver are not the same set of people
[18:53:24] <SWPadnos> heh
[18:53:42] <SWPadnos> if only the people who want to use it were willing to pay the people who can write the driver :)
[18:53:53] <jmkasunich> and provide the hardware to test on
[18:53:58] <SWPadnos> or at least provide hardware for testing
[18:54:00] <SWPadnos> right
[18:54:11] <jmkasunich> note: AND not OR
[18:54:16] <SWPadnos> right :)
[18:54:43] <SWPadnos> * SWPadnos isn't feeling too well, so the brain is running on 2 cylinders
[18:56:10] <jmkasunich> * jmkasunich is abusing geckos
[18:56:18] <jmkasunich> and stepgen, and freqgen, etc
[18:56:22] <SWPadnos> heh
[18:56:50] <SWPadnos> did you try connecting the motor to something to move the resonance point?
[18:56:55] <jmkasunich> no
[18:57:14] <jmkasunich> I suspect that belted to a leadscrew it will be much less pronounced
[18:57:25] <jepler> http://emergent.unpy.net/index.cgi-files/sandbox/gcode-spline-working.png
[18:57:26] <jmkasunich> and I'm all but certain that isn't the cause of the stuff I'm trying to track down
[18:57:33] <SWPadnos> yeah, though you may end up with bad part finish
[18:57:46] <SWPadnos> jepler, much better :)
[18:57:51] <jmkasunich> jepler: the other pictures were much more "interesting"
[18:58:06] <jepler> jmkasunich: indeed
[18:58:07] <cradek> jepler: wow, that's neat
[18:58:44] <cradek> magnitude velocity plot is still the same I assume?
[18:58:57] <jepler> currently AXIS is using a hard-coded 100 line segments per spline, and emc is using a hard-coded 20 arcs per spline
[18:59:06] <jepler> cradek: I haven't looked yet, but that's what I expect..
[19:00:15] <jepler> cradek: yes, basically the same
[19:02:39] <cradek> fwiw G5 is "unassigned" in rs274d/1980 according to my book
[19:03:21] <jepler> that's comforting
[19:03:27] <jepler> there's not a spline code is there?
[19:04:47] <jepler> http://emergent.unpy.net/index.cgi-files/sandbox/g5-spec.png
[19:05:29] <jmkasunich> are K and R free?
[19:05:39] <jmkasunich> (for eventual extension to 3D
[19:05:44] <jepler> jmkasunich: yes
[19:05:47] <cradek> jepler: no I don't see anything about splines
[19:06:37] <jepler> K and R are both used in G2/G3 arcs as floats
[19:06:50] <jmkasunich> good
[19:08:23] <cradek> I suggest reversing PQ so they are alphabetical too
[19:08:43] <jepler> oh -- I think they are, and the picture's wrong.
[19:09:26] <jmkasunich> hmm
[19:09:56] <jmkasunich> if you are stringing bunches to gether, the I and J of move N are -P and -Q of move N-1
[19:09:56] <cradek> also can you remove one arrow on all the dims to (sort of) show the signs?
[19:10:05] <jepler> cradek: btfoom
[19:10:30] <jepler> jmkasunich: yes, that's why (I- J-) is parenthesized -- it's optional and is found in the way you suggest
[19:10:34] <jepler> if not specified
[19:10:45] <jmkasunich> oh, cool
[19:10:46] <jepler> squint at the code on the bottom of
http://emergent.unpy.net/index.cgi-files/sandbox/gcode-spline-working.png
[19:11:24] <cradek> neat
[19:12:22] <jepler> next item of business: Change segment joining in G64 P- mode to fit arcs to the path within the tolerance, as shown here:
http://www.cosy.sbg.ac.at/~held/projects/biarcs/img/113_ba.gif
[19:12:40] <lerman> More than neat. Is there some way to use the precision (blending) spec to control the number of segments?
[19:12:55] <cradek> haha
[19:13:06] <jepler> lerman: not yet, it's a pretty basic implementation right now
[19:13:30] <jepler> lerman: I'd *like* the G64 P- blending tolerance to be used instead of a hard-coded "20 arcs per spline", which is what it does now
[19:13:39] <jmkasunich> jepler: tell me again why the arc-fitting instead of general spline?
[19:13:50] <jmkasunich> something about not being able to control the velocity along the path?
[19:14:32] <jepler> jmkasunich: there's not an easy way to convert a spline so that the parameter is length, or put another way the velocity varies over the spline if you treat "t" as a time parameter
[19:14:42] <jmkasunich> right
[19:15:28] <jmkasunich> but the various f(t) that produce the coordinates x(t), y(t), z(t), all are cubic polys in t, right?
[19:15:33] <lerman> So, instead you approximate the spline by arcs? Why not still cut the spline but approximate the velocity with what you would have if you were cutting arcs?
[19:16:21] <jepler> jmkasunich: yes
[19:16:31] <jmkasunich> if they are cubic polys in t, I believe the derivitaves are closed form (actually one order lower IIRC)
[19:17:00] <jmkasunich> so when you are at t = whatever, you can compute dx/dt(t), etc
[19:17:13] <jmkasunich> and thus v(t)
[19:17:22] <jepler> jmkasunich: if you're offering to complete the implementation of splines all the way down to the realtime level, I accept.
[19:17:24] <jmkasunich> which you want to be constant at f
[19:17:33] <jmkasunich> not right now
[19:17:48] <jmkasunich> what I am doing is a thought excersize to see where my ideas fall flat
[19:18:09] <jmkasunich> if they don't, then yes, one of these days I'll go for it
[19:18:19] <jmkasunich> but if I'm missing something that makes the task near impossible, then...
[19:18:42] <jmkasunich> so, you are at t= whatever, you've computed v(t) (order O(1))
[19:19:01] <jmkasunich> t = Tn lets say
[19:19:42] <jmkasunich> if you know v(Tn), you can calculate Tn+1 such that you get the desired v
[19:19:43] <jepler> yes you can compute the derivative of the spline easily, I use it to find tangents to the spline at desired points
[19:19:52] <jmkasunich> (or a reasonable approximation thereof)
[19:20:02] <jmkasunich> without ever knowing the overall length
[19:20:20] <jmkasunich> I suspect the shit hits the fan when you think about blending, which need to know distance to go...
[19:20:27] <jepler> you need the overall length to .. yes exactly
[19:20:46] <lerman> jmk: I think you are on the right track. Also, by computing the new position and adjusting the velocity at each servo cycle, you will divide the spline into the number of segments as well as you can given the servo cycle time.
[19:21:12] <jepler> you can approximate the length in the same fashion as you approximate velocity
[19:21:22] <lerman> (worded poorly)
[19:21:32] <lerman> (my words, that is)
[19:21:46] <jmkasunich> lerman: the problem with that approach is you are dividing into just the "huge number of tiny segments" that gives blending and lookahead fits
[19:21:57] <jepler> 13:04:22 <andrew> jepler: i think its becaue i didnt turn off the modem to reboot it just my cpu
[19:22:01] <jepler> oops
[19:22:30] <jepler> trying to help someone with his stupid windows computer, and this is what he just said to me ^^
[19:22:31] <lerman> How often does a circle get broken into parts?
[19:22:48] <jmkasunich> if you don't need lookahead, the derivative approach works, and is O(1)
[19:23:20] <jmkasunich> if you do need lookahead, the derivative method means you need to precompute the whole spline so you can work out where in it you need to begin your decel, etc
[19:24:43] <jmkasunich> actually, that is the general problem with all lookahead - general lookahead may be forced to look ahead an arbitrary number of "segments", whatever segments are
[19:24:49] <lerman> Precomputing is bad because? (a) it doesn't fit the current structure? (b) it takes too much memory? (c)??? (d) all of the above?
[19:25:33] <jmkasunich> the work done in the TP each servo cycle needs to be O(1), or at least O(n) for some very small and bounded n
[19:25:46] <lerman> Compared to memory in the 1980s when a lot of this stuff was conceived, we have infinite memory, today.
[19:26:13] <jmkasunich> precomputing in user space has limits though
[19:26:17] <lerman> [Also infinite processor.]
[19:26:34] <jmkasunich> suppose you hit a limit or the user changes something while you are running your precomputed path
[19:26:43] <jmkasunich> toss the computations out the window and start over
[19:27:00] <lerman> Hitting a limit is 'fatal', anyway.
[19:27:07] <jmkasunich> "changes something" = feedhold, abort, feed override
[19:27:11] <alex_joni> lerman: the infinite memory isn't always true for kernel space
[19:27:13] <jepler> lerman: limit of acceleration or velocity
[19:27:15] <jepler> not of machine travel
[19:27:17] <jmkasunich> limit was a bad example
[19:27:30] <lerman> The interpreter already runs way ahead of realtime.
[19:27:48] <jmkasunich> suppose we're talking about a linear move, and you are probing - when the probe touches, you need to stop
[19:28:22] <lerman> Well, probing already stops interpreter lookahead.
[19:28:26] <jmkasunich> lerman: yeah, it does - and that causes all manner of grief too - when somebody hits abort and the line displayed on the GUI bears no resemblence to the line that was actually running, etc
[19:28:35] <jmkasunich> probing is just one case
[19:29:12] <jmkasunich> adaptive feed - changing the feedrate mS by mS based on voltage (for edm) or spindle load current (milling, routing)
[19:29:43] <lerman> The GUI issue is a defect (IMHO). The GUI should have a way to show the 'actual' current position.
[19:30:03] <jmkasunich> yeah, and that defect has largely been handled
[19:30:46] <jmkasunich> but it illustrates the larger issue of time and precomputation as a substitute for realtime calculations
[19:31:04] <jmkasunich> if the interp could run in realtime, you wouldn't need to jump thru those hoops
[19:31:56] <jmkasunich> but sooner or later you have to get out of realtime - even if the interp was infinitely fast and ran in realtime, the g-code itself is being served up from a disk that has latency, and is managed by a non-rt OS
[19:31:57] <lerman> Is there any evidence that the interp couldn't run in real time? (Or be improved slightly, so it could?)
[19:32:19] <alex_joni> lerman: first of all it's c++ .. which isn't always kernel friendly
[19:32:22] <jmkasunich> I wasn't suggesting that a RT interp was the answer at all
[19:32:40] <jmkasunich> just trying to make a point
[19:32:51] <jepler> More importantly, a user reports that his loop variable has advanced to 20 when he aborted after 5 runs
[19:32:58] <jepler> that's the readahead problem
[19:33:15] <jepler> or that a modal code from the last line of the program has been applied, even though he aborted before then
[19:33:29] <lerman> I wasn't suggesting that the current interp should be RT'd. I'm just trying to understand the problem space.
[19:33:31] <jepler> but as usual we've strayed far from the subject at hand
[19:33:33] <jmkasunich> consider conditional branches in g-code for example... the interp can't test the condition ahead of time (assuming the condition is some physical thing on the machine, not just a variable in the g-code)
[19:33:54] <jmkasunich> jepler: yeah, I tend to stray
[19:34:08] <lerman> Well, right now, there aren't many inputs to the interp.
[19:34:15] <jmkasunich> I'm always trying to figure out the general problem, and I usually get nowhere
[19:34:24] <lerman> (Although I'm in favor of adding the ability to have more).
[19:34:28] <jmkasunich> certain other people just attack a subset of it and get things working
[19:35:19] <jmkasunich> lerman: the key to using g-code subroutines to do toolchanges (for example) is exactly that - the ability for g-code to test machine status
[19:35:32] <jmkasunich> but that brings us right back to the lookahead issue
[19:35:51] <jmkasunich> sometimes the interp can work ahead, other times it can't
[19:36:19] <lerman> No. The reason for the interp to do lookahead is so that it doesn't stall the pipeline. But there is no pipeline (and shouldn't be) in the middle of a toolchange.
[19:36:40] <jmkasunich> iow: "sometimes the interp can work ahead, other times it can't"
[19:36:51] <jmkasunich> some operations can (and need to) be pipelined
[19:37:00] <jmkasunich> others can't and/or shouldn't
[19:37:13] <lerman> The pipeline is so that the tool keeps cutting during changes in direction. We don't want to stop the feed while we are cutting a curve.
[19:37:30] <jmkasunich> right
[19:37:32] <lerman> Particularly if the material will work harden or if finish is important.
[19:38:09] <jmkasunich> pipelineable operations are really the exception, not the rule
[19:38:17] <lerman> But -- back to splines, we want them to cut continuousousuously (never could get my fingers to type that right).
[19:38:26] <jmkasunich> heh
[19:38:34] <jmkasunich> right, they are in the same class as arcs and lines
[19:38:58] <jmkasunich> you should be able to go line; arc; line; spline; spline; arc; spline; etc
[19:39:03] <jmkasunich> and have the tool never stop
[19:39:41] <jmkasunich> assuming the appropriate G6x mode is in effect
[19:40:38] <lerman> I notice you didn't have two lines in a row -- depends on the angle between them and the tolerance. But if the parts have the same tangent (or mathematically, if the derivatives are continuous) there should be no stops.
[19:40:58] <jmkasunich> actually that wasn't on purpose
[19:41:12] <jmkasunich> I didn't rigorously list all the combinations
[19:41:28] <lerman> After I typed it, I guessed that.
[19:41:31] <jmkasunich> with blending enabled, line to non-tangent line is ok
[19:42:59] <lerman> Should also be OK for arc to arc, arc to spline, etc. Blending is the process of inserting an arc that is tangent to the incoming and outgoing components. (I don't intend the word 'arc' to mean circular arc -- could be a spline, hyperbola, etc)
[19:43:38] <lerman> [add to previous defn of blending -- while maintaining a specified tolerance]
[19:43:39] <jmkasunich> one interesting thing about that endpoint+tangent notation that jepler proposed for G5... it carries the critical info for blending
[19:44:14] <jmkasunich> everything, line, arc, and spline, has endpoints and endpoint tangents, and that is most of what you need to know to blend
[19:44:37] <lerman> jepler: did you lift that notation from someplace? That specification is brilliant... it would be nice if someone I knew could claim credit for it.
[19:45:08] <jmkasunich> normal spline notation is 2 endpoints and 2 control points
[19:45:19] <jmkasunich> the key here is that the control points are specfied as relative to the endpoints
[19:45:52] <lerman> Definitely slick.
[19:46:17] <jepler> lerman: which notation?
[19:46:36] <jepler> G5 I-J- P-Q- X-Y-?
[19:46:41] <jmkasunich> g5-spec.png
[19:46:49] <lerman> The idea of specifying the control points as relative to the endpoints.
[19:47:02] <jepler> I made it up, but it's pretty obvious given that gcode already specifies arc centers that way
[19:47:14] <jmkasunich> dang - 55C is HOT to the touch
[19:47:29] <alex_joni> you can still keep your finger there
[19:47:46] <jmkasunich> not for long
[19:47:49] <jmkasunich> 10 seconds maybe
[19:47:58] <alex_joni> 70 is hot to touch
[19:48:30] <jmkasunich> maybe I'm just a wimp
[19:48:34] <jmkasunich> meter says 55C
[19:48:34] <alex_joni> 55C is a bit more than a hot tub :D
[19:48:54] <jmkasunich> fingers say "leggo now please"
[19:49:25] <jmkasunich> maybe I should go boil some water and check my meter
[19:49:30] <lerman> With a small amount of work, I could get the interpreter to handle G5 as an oword subroutine. -- without changing the notation that the programmer uses.
[19:49:54] <lerman> That would be neat for playing.
[19:50:06] <alex_joni> jmkasunich: 131F.. does that still sound hot to you?
[19:50:20] <lerman> It would get pretty tricky to try to figure out how many segments to use, though.
[19:50:23] <jmkasunich> alex_joni: its not a C/F thing (I use C all the time for electronics work)
[19:50:34] <jmkasunich> its a numbers on display to fingers thing
[19:50:39] <alex_joni> jmkasunich: oh, ok.. it just seems not that hot to me :)
[19:50:52] <alex_joni> I'm used to 200C+ welded parts :D
[19:50:52] <jmkasunich> * jmkasunich goes to check the meter
[19:52:59] <DavidMB> Hi Alex_joni, sorted out problem of spindle-on, after unplugging lead from port and metering output signal was coming out ok, after re-connecting controller everything worked ok. Thank's for your help earlier.
[19:53:52] <alex_joni> DavidMB: no problem, glad it's working
[19:53:58] <alex_joni> hope you're happy with emc2 :)
[19:55:11] <DavidMB> Looking forward to being able to use all the easy config stuff for separate home and limit switches, always a pain with EMC1.
[19:58:29] <jmkasunich> meter works, its just my fingers that need calibrating
[19:59:15] <jmkasunich> water boils at 97-98C, ice is at 3C ;-)
[20:06:41] <lerman> Are you high? :-) That would explain the BP error.
[20:06:59] <jmkasunich> no ;-)
[20:07:13] <jmkasunich> thermal gradient in the probe explains the errors
[20:07:42] <jmkasunich> tip in boiling water, body in ambient - sensor isn't perfectly coupled to tip or perfectly isolated from body
[20:27:36] <awallin> for intensive 3D work (lot's and lot's of small linear segments), maybe a separate trajectory planner with precomputed trajectory would be OK? A simple implementation would have to disable feed-override, but it would give the added benefit of "infinite" lookahead. Some users do complain about the current blending capability (I haven't tested 2.1 extensively yet, but I intend to run some moulds etc later in the spring)
[20:28:35] <cradek> I think anyone worried about TP performance should check out matt timmermans's work before anything else
[20:29:14] <jmkasunich> quickstep? or something else?
[20:29:23] <cradek> I don't think we should settle for anything that doesn't allow feed override changes, for instance, and we should have exactly one planner
[20:29:38] <cradek> no, quickstep is a different ball of wax
[20:29:49] <jmkasunich> I thought so
[20:29:52] <jepler> quickstep ~= emc2 stepgen
[20:29:56] <jepler> but he also changed the trajectory planner in bdi
[20:29:56] <jmkasunich> so what work are you talking about?
[20:30:33] <cradek> he wrote a different planner for bdi4emc, there was some talk about it on the lists a while back
[20:32:03] <alex_joni> http://www.youtube.com/watch?v=MPG-LYoW27E&NR
[20:32:04] <lerman> Re: feed override. Decreasing the feed isn't a problem. Increasing it can be a problem. But increasing the feed *always* takes time. So, are we just talking about degree. How long does it take for each planner to increase to the new speed?
[20:41:10] <cradek> alex_joni:
http://www.youtube.com/watch?v=Kw0sP7WKHXY
[20:42:54] <alex_joni> cradek: haha
[20:43:11] <cradek> that's about how I felt about it
[20:47:51] <SWPadnos> it reminds me a bit too much of LabView
[20:48:00] <anonimasu> lol
[20:49:26] <anonimasu> retractable is a damn cool thin :)
[20:50:37] <SWPadnos> I like the technology of the display/input interface
[20:50:58] <SWPadnos> and it's pretty neat that the yhave blocks with different shapes/codes on them to do different thing - that's very cool
[20:51:06] <anonimasu> damn..
[20:51:07] <anonimasu> yeah
[20:51:09] <anonimasu> http://www.youtube.com/watch?v=0h-RhyopUmc&mode=related&search=
[20:51:20] <anonimasu> around 2:50
[20:51:21] <anonimasu> damn
[20:51:25] <anonimasu> I'd love that UI..
[20:55:48] <SWPadnos> cool - the interface software is open source:
http://mtg.upf.edu/reactable/?software
[20:56:09] <anonimasu> I'
[20:56:19] <anonimasu> I'd love to have a cad program that worked with that kind of controls..
[20:56:35] <anonimasu> rather one of thoose multipoint touchscreens..
[20:57:03] <SWPadnos> yeah - those screens are acutally using optical information, I think
[20:57:22] <anonimasu> yep
[20:57:39] <anonimasu> it says so on their page
http://mtg.upf.edu/reactable/
[20:57:46] <anonimasu> translucent table.
[20:58:36] <anonimasu> http://www.youtube.com/watch?v=Jm39v_MdnzM&mode=related&search=
[20:58:37] <anonimasu> pretty cool too
[21:01:32] <xemet> those things are wonderful!!
[21:02:09] <anonimasu> agreed..
[21:07:18] <anonimasu> I'd love a table like that for controlling lighting.
[21:07:20] <anonimasu> ;)
[21:07:30] <alex_joni> http://www.youtube.com/watch?v=DbtJIq3SRcg&eurl=
[21:09:30] <lerneaen_hydra> alex_joni; ... that music is *not* what I was expecting
[21:15:11] <xemet> http://www.youtube.com/watch?v=D4ECEAj3Ob4&eurl=
[21:18:54] <lerneaen_hydra> that system is just begging for accidents and a fault where the poles will rise while the bus is still there
[21:23:40] <jmkasunich> if they had that in the US a laywer would set up a stand right next to it
[21:24:08] <jmkasunich> stupid person hits it, files sues the govt
[21:24:36] <SWPadnos> it's in England, and at least one town has people lobbying/suing to get rid of them
[21:24:51] <jmkasunich> I especially like the second one - she actually accelerates to sneak in behind the bus, whams into it hard enough to fire the airbags
[21:25:07] <jmkasunich> then runs around to the back "oh, my baby"
[21:25:25] <jmkasunich> stupid
[21:25:27] <SWPadnos> yeah - oops - what happened?
[21:27:08] <cradek> wow that second one really nailed it
[21:27:34] <jmkasunich> stomped on the gas trying to sneak thru behind the bus
[21:41:59] <awallin> lerman: re feed override: the current approach is that the tp reacts immediately to a new (possibly higher) feed-override. If we wanted a deeper lookahead buffer then I guess we would have to accept a more sluggish response to increased feed override (immediate response to lowered feed-override is probably doable)
[21:44:11] <lerman> Well, sluggish is relative. A few second lookahead would probably be sufficient. If it took a few seconds to react to a feed increase, that probably wouldn't be a big problem.
[21:45:52] <lerman> The lookahead time should be roughly the amount of time to decelerate from the current velocity to zero.
[21:46:26] <jmkasunich> which on any reasonably responsive machine is under a second
[21:46:37] <SWPadnos> a few seconds probably would be a problem for people who use FO
[21:46:58] <SWPadnos> I think the main use for FO is for someone to "tune" the speed
[21:47:15] <SWPadnos> which they do by listening to / watching the machine cut
[21:47:40] <Skullworks> How is feed hold / resume handle now, I would think it would function nearly the same.
[21:49:05] <awallin> I think feed hold just sets feed override to zero
[21:49:56] <alex_joni> awallin: right
[21:50:56] <Skullworks> so when feedhold is released the machine accels at G00 rate until it reaches the Fxx velocity?
[21:51:20] <jmkasunich> it accels at max
[21:51:31] <jmkasunich> G0 is a velocity, not an accel rate
[21:52:06] <awallin> Does anyone have a problem with the tp and short segments with an actual machine currently? I'd be motivated to work on this if there is a real problem, but I won't be able to test on my own machine in a few months still
[21:52:41] <lerman> The discussion started with the question of how many segments a spline should have. I suggested that if we used one segment per servo position update, we could do no better. (more precise). A response was that TP would not be happy because it has limited lookahead and there might be a blending issue. Then I suggested that TP could have as much lookahead as we needed (memory is cheap). The...
[21:52:43] <lerman> ...response was that then feed override would be sluggish. And here we are.
[21:53:15] <awallin> ah, right.
[21:53:36] <SWPadnos> blending and FO (plus other user controls) are at cross purposes in the TP
[21:54:11] <SWPadnos> ideal belnding could be as complex as an iterative operation over the entire file, but that has zero compatibility with user overrides
[21:54:42] <lerman> I asked (but didn't get an answer) how circles (arcs) are handled. How many segments are they broken in to.
[21:54:47] <awallin> so I suggested a blend mode which does not allow FO>1
[21:55:05] <awallin> lerman: a circle is an 'intrinsic' move that the tp knows about
[21:55:12] <jmkasunich> circles aren't borken into segments
[21:55:11] <awallin> it knows about lines and arcs
[21:55:14] <jmkasunich> broken either
[21:55:41] <SWPadnos> the only "segmentation" is that there is only one velocity update per planner period
[21:55:43] <jmkasunich> a circle is well behaved mathemetically - if you know you have to stop at the end, its not hard to figure out when to begin slowing down
[21:55:50] <lerman> But the servos (or steppers) know only line segments. So in that sense, they are broken.
[21:56:14] <lerman> How long is a planner period? Is that the same as a servo cycle?
[21:56:19] <SWPadnos> yes, but the motors themselves don't let you do a step change in velocity
[21:56:29] <jmkasunich> true, but I'm not talking about that - thats basically just sampling the path at the servo rate
[21:56:31] <SWPadnos> I'm not sure. I think it is, but it doesn't have to be
[21:56:42] <awallin> yes, but an arc is only one entry in the tp stack of commands, not many small line segments
[21:57:04] <Skullworks> Once upon a time there was a blurb in the fine print about FANUC specs which advised that the machines repeatability spec was only valid up to 159 IPM and that there would be following errors when FO was used in high speed contouring.
[21:57:14] <lerman> So arcs don't drive the TP crazy.
[21:57:27] <jmkasunich> not usually
[21:57:29] <Skullworks> this was circa 1908
[21:57:36] <Skullworks> 1980
[21:57:50] <jmkasunich> although if you put a bazillion very short arcs together in a row, it would be just as bad as a bazillion lines
[21:58:24] <SWPadnos> in fact, you may only need 0.9 bazillion arcs, since the computational loadis a little higher with arcs
[21:58:35] <jmkasunich> heh
[21:59:10] <SWPadnos> has anyone been in touch with Les Watts recently?
[21:59:11] <lerman> It isn't a computational load issue -- it's an algorithmic lookahead issue.
[21:59:40] <SWPadnos> it may be good to see if he's interested in doing some EMC2 testing on his high performance machine ...
[21:59:50] <lerman> I seem to recall that he was interested in the issue.
[21:59:59] <lerman> And had some ideas.
[22:00:09] <awallin> I think the problem now is that the stack of canon commands (linear or arc) are processed in RT, so throughput there becomes a computational load problem.
[22:00:45] <alex_joni> awallin: the bottleneck is getting loads of small lines from userspace to rt
[22:00:57] <SWPadnos> I'm pretty sure there are spline types that have relatively easily calculated lengths
[22:01:04] <alex_joni> and lookahead which emc2 doesn't do that well
[22:01:12] <awallin> if you dissallow FO, the whole trajectory can be precomputed, no processing of canon commands needed in RT
[22:01:20] <lerman> That shouldn't be. Just use a somewhat larger buffer and transfer more lines at a time.
[22:01:48] <alex_joni> lerman: I think it's one / cycle now
[22:02:03] <SWPadnos> remember that there are G-code files that are in the gigabyte range. preprocessing isn't a good option for those
[22:02:03] <awallin> still, when processing the canon commands, currently it's not possible to process more than one command per cycle
[22:02:40] <lerman> One 'problem' is that we must design for the worst case -- lot's of sjprt lines at large different angles at high speed.
[22:02:59] <SWPadnos> sjprt?
[22:02:59] <awallin> so if you have close to, or over one linear segment per cycle (thats 1000 segments/s if TRAJ=0.001 I think) there will be a problem
[22:03:04] <lerman> But most of the time it really isn't an issue.
[22:04:28] <lerman> sjprt => short
[22:04:32] <SWPadnos> ah
[22:05:43] <fenn> we just need a realtime CAM algorithm :)
[22:06:00] <awallin> how does that solve anything ?
[22:06:16] <SWPadnos> you can change the model in realtime, and have the achine make the new design :)
[22:06:20] <SWPadnos> machine
[22:06:33] <SWPadnos> the only problem is adding metal :)
[22:06:35] <lerman> Why can't we preprocess gigabyte GCode files? Disk space is cheap.
[22:06:57] <fenn> SWPadnos: that's genius!
[22:08:08] <lerman> Remember that the TP problem is essentially one of assuring that we run at maximum feed consistent with the tolerance and feed rate constraints.
[22:08:16] <SWPadnos> there's always some problem. one is time: if it takes 50 ms to preprocess a line, and there are 20 million lines in the file, it'll take ~12 days to preprocess
[22:08:29] <fenn> 50ms is ages
[22:08:37] <SWPadnos> even at 1.2 ms (just longer than the servo rate, it's ~1.5 days
[22:09:07] <fenn> thats 60000000 cycles on my machine
[22:09:11] <lerman> It clearly should not take longer to preprocess than to actually process. So, that would assume a machining time greater than 12 days.
[22:09:30] <SWPadnos> it's OK for the machine to take that long (it has to), but to make someone wait for the preprocessing would be bad
[22:09:58] <SWPadnos> the only reason for preprocessing is that you can't meet the RT deadlines for processing
[22:10:05] <lerman> When we precompute the TP, we could also compute it for the case of differing (increasing) feeds.
[22:10:05] <SWPadnos> so it must be longer to preprocess than to process
[22:10:34] <awallin> SWPadnos: how about the problem with more than one segment per cycle?
[22:10:44] <a-l-p-h-a> sup folks?
[22:10:58] <SWPadnos> good idea - I thikn I'll grab a bite
[22:11:12] <awallin> it doesn't necessarily take longer than one cycle to process a short segment, you just need them at a throughput higher than one segment per traj cycle
[22:11:35] <lerman> No. Batch processing could (should) be faster than RT. Also, RT must handle the worst case, while batch just takes longer to do it.
[22:12:06] <lerman> At any rate, the preprocessing was just a thought experiment. A few second lookahead would be more than enough.
[22:12:11] <SWPadnos> you can't have more than one segment per TP cycle - the only way to get higher throughput is to collapse multiple segments into larger single segments
[22:12:23] <SWPadnos> (and/or speed up the TRAJ loop)
[22:12:50] <awallin> SWPadnos: that's how it currently works, and I agree that programming more than one segment per cycle is not a great idea...
[22:13:03] <SWPadnos> these ideas come up pretty regularly, and it seems there's a pathological case that screws up any of them :)
[22:13:15] <lerman> When you get to the point that one segment per TP cycle isn't fast enough, you need faster servo cycles and (possibly) a faster machine.
[22:13:20] <SWPadnos> awallin, it's not possible - you can only generate one endpoint per TRAJ cycle
[22:13:31] <lerman> Les was looking at that, I think.
[22:13:34] <SWPadnos> so you can't have multiple segments per cycle
[22:13:45] <SWPadnos> yes, Les was looking at that
[22:14:06] <SWPadnos> he specifically wanted to use PCI cards because the ISA ones can't seem to support a fast enough servo loop
[22:14:24] <lerman> I've got to get some work done. I'll see you later.
[22:14:25] <Jymmmm> Les Who?! Surely you can't be speak of Les Watts
[22:14:30] <SWPadnos> (he maxed out at ~2 KHz for ISA, but someone had done 8 KHz with the PCI version of the same card)
[22:14:30] <Jymmmm> ^ing
[22:14:37] <lerman> Yes. Les Watts.
[22:15:12] <lerman> The problem is that the fast machines still have long latencys. The x86 seems to be designed for throughput, not latency.
[22:15:15] <Jymmmm> lerman: No, no, no... Les Watts is just a figment of your imagination.
[22:15:36] <SWPadnos> recent versions of the x86 certainly are designed for throughput at the sxpense of latency
[22:15:58] <SWPadnos> I'd expect the AMD cores to be batter for latency, due to the very deep pipelines of the P4
[22:16:06] <SWPadnos> bettter, even
[22:16:17] <SWPadnos> I haven't tested that theory though
[22:16:23] <SWPadnos> (I have no recent Intel chips :) )
[22:16:30] <Jymmmm> SWPadnos But have you tested the touchscreen
[22:16:33] <lerman> How fast are the fastest power PCs?
[22:16:48] <lerman> Or SPARCs?
[22:16:51] <fenn> if you can get 50khz i/o from a parport, how is it a problem to get 8khz servo update rate?
[22:16:50] <SWPadnos> lerman, the ones with 20 cores, or the ones that humans can afford?
[22:17:25] <SWPadnos> fenn, you aren't using FP in the thread that deals with the parport, and it's only 2 or 3 bytes of I/O
[22:17:37] <SWPadnos> a full servo cycle will be many reads and writes
[22:17:51] <SWPadnos> err - getting / sending full servo data is many reads/writes
[22:18:08] <fenn> hm i figured it'd be only one read and one write
[22:18:12] <SWPadnos> look at the USC - that takes ~50 uS for a full update on 4 axes
[22:18:31] <SWPadnos> no - you need to read position and digital inputs, and write DACs and digital outputs
[22:18:36] <SWPadnos> for each axis
[22:18:39] <Jymmmm> SWPadnos: You saying that a dual cpu/core will yield less latency?
[22:18:45] <SWPadnos> Jymmmm, no
[22:18:48] <fenn> yes but you can do all the reading at once and all the writing at once
[22:18:51] <Jymmmm> SWPadnos ok, carry on
[22:19:02] <fenn> so with "burst" mode like epp you can just dump it all in one go
[22:19:24] <fenn> er, two goes
[22:19:29] <SWPadnos> fenn, yes, but since ISA is just like that parallel port (except for width), it still takes ~1 uS per read or write
[22:19:45] <Jymmmm> SWPadnos and PCI instead of ISA?
[22:19:44] <fenn> yeah that's what i'm saying
[22:19:57] <SWPadnos> Jymmmm, yes - that's what I was saying is faster
[22:20:03] <Jymmmm> SWPadnos k
[22:20:50] <lerman> How fast is a modern FPGA? One that I could program a processor in.
[22:21:14] <SWPadnos> lerman, a $20 FPGA or a $10000 FPGA? :)
[22:21:20] <fenn> the processor would be slower than a real hardware processor
[22:21:53] <lerman> Are there $10000 FPGAs?
[22:21:56] <SWPadnos> yep
[22:22:03] <fenn> and up
[22:22:20] <SWPadnos> I haven't seen any on the market for more than $12k or so
[22:22:26] <fenn> (i guess it always goes up if you have the money to pay)
[22:22:28] <lerman> Damn. I'm in the wrong business :-)
[22:22:33] <Jymmmm> fpga for $10K, better come with a free BJ attatchment
[22:22:52] <SWPadnos> they're too small
[22:22:59] <lerman> What sort of mill do I need to make FPGAs?
[22:23:08] <alex_joni> lol
[22:23:08] <SWPadnos> a micromill, of course ;)
[22:23:12] <Jymmmm> O_o
[22:23:17] <fenn> a nanomill
[22:23:20] <skunkworks> nanomill
[22:23:23] <Skullworks> angstroms
[22:23:24] <Jymmmm> picomill
[22:23:41] <SWPadnos> an attomill
[22:23:43] <lerman> I'm using pico systems boards. I suppose that doesn't count.
[22:23:43] <skunkworks> quantumill
[22:23:51] <Jymmmm> lerman LOL
[22:24:52] <lerman> SWPadnos: weren't we going for dinner? Who's buying?
[22:24:54] <Skullworks> I'm prolly going to get a USC at some point... I still have to finish the motor mounts...
[22:24:54] <fenn> lerman: softcore cpu's can go into hundreds of megahertz
[22:25:09] <Jymmmm> Well, almost done rewiring the machine... just need to find/order the crimpers
[22:25:17] <SWPadnos> I was going for dinner. thanks for reminding me :)
[22:25:27] <SWPadnos> lerman, where are you located?
[22:25:35] <lerman> A pair of pliers and a soldering iron work OK in a pinch.
[22:25:41] <lerman> CT
[22:25:49] <SWPadnos> ah -close to here but not that close :)
[22:26:05] <alex_joni> SWPadnos: I'm closer :D
[22:26:27] <lerman> In that case, I'll offer to buy (if you drive over). :-)
[22:26:30] <SWPadnos> hmmm - to what? ;)
[22:26:42] <lerman> I'm off (for dinner).
[22:26:46] <SWPadnos> lerman, it's a deal :)
[22:26:48] <SWPadnos> see you later
[22:26:49] <Jymmmm> lerman: Yeah, but I've spent so much time making it nice energy chian, split loom tubing, etc, I'd like the molex connectors to have a nice crimp as they also have a bit of strain relief too.
[22:27:10] <fenn> use a strain relief then
[22:27:33] <Jymmmm> fenn I am, as soone as I buy the crimpres =)
[22:27:35] <skunkworks> crimp? solder.
[22:27:50] <skunkworks> * skunkworks hates crimp connections/
[22:27:51] <fenn> crimp and solder?
[22:28:02] <Jymmmm> solder = brittle
[22:28:22] <fenn> thats what the strain relief is for
[22:28:33] <skunkworks> crimp = yeck :)
[22:28:47] <skunkworks> its just me.
[22:28:54] <Jymmmm> Plus I'll be able to use the crimpers on the other driver box I have in mind if I get geckos.
[22:29:06] <skunkworks> I crimp my spade connectors and then solder them.
[22:29:39] <SWPadnos> http://www.ch601.org/resources/crimpsolder.htm
[22:29:48] <skunkworks> wife says I am an 'over doer'. I have no clue what she is talking about
[22:29:50] <Jymmmm> skunkworks buy good crimpers and you won't need to do all that =)
[22:30:05] <Jymmmm> not $0.99 flea market specials =)
[22:31:00] <alex_joni> http://www.automarket.ro/img/db/article/001/669/240986l.jpg?ts=1170244434
[22:31:27] <Jymmmm> alex_joni that is so bad
[22:31:39] <alex_joni> D'Vinci Forgiato Radurra clear polycarbonate wheels
[22:31:46] <alex_joni> http://www.ministryoftech.com/2006/11/02/d.vinci-forgiato-radurra-clear-polycarbonate-wheels/
[22:31:49] <Jymmmm> clear?!
[22:32:09] <SWPadnos> that is cool :)
[22:32:12] <skunkworks> ohhh - I want those for my car
[22:32:16] <alex_joni> Jymmmm: transparent
[22:32:18] <jtr> lerman:
http://home.triad.rr.com/landj07/jimages/MicroMill.jpg - a small mill seen at Cabin Fever. bbl
[22:32:44] <skunkworks> I wonder if that wieghs less that a light aluminum rim.
[22:32:56] <SWPadnos> jtr, it even has a rear shaping head :)
[22:34:29] <Jymmmm> wondr if it's functional
[22:34:52] <SWPadnos> lexan is very strong, so it's entirely possible that the car is drivable
[22:35:12] <xemet> http://www.craftsmanshipmuseum.com/Spielmann.htm
[22:35:23] <Jymmmm> I mant the mico BP
[22:35:38] <xemet> look at this 5 axes "desktop" mill...
[22:35:49] <SWPadnos> oh that - I was wondering the same thing
[22:36:05] <SWPadnos> there was a switch, so I'll bet the spindle turns
[22:36:08] <xemet> http://www.craftsmanshipmuseum.com/images/SpielCin2.JPG
[22:36:34] <SWPadnos> nice
[22:37:52] <SWPadnos> on the solder/crimp discussion: good soldering is worse than good crimping in situactions where the wire may flex
[22:38:00] <SWPadnos> though I can't find the paper that told me that
[22:38:27] <SWPadnos> you can tell why though: when you solder, you make a very stiff area in the wire (I'm assuming stranded here)
[22:38:29] <alex_joni> http://www.automarket.ro/img/db/article/001/661/308896l.jpg?ts=1170195176
[22:38:57] <SWPadnos> all flexing occurs at the end of the stiff part, causing that to break
[22:39:08] <skunkworks> swpadnos: I understand - I just don't have to like it ;)
[22:39:11] <Jymmmm> SWPadnos: that's what I read/told
[22:39:31] <SWPadnos> a crimp has a longer region over which the bends can occur, so there's less stress when ther wire flexes
[22:39:55] <SWPadnos> heh
[22:40:04] <SWPadnos> ok. now it's really dinnertime
[22:40:06] <SWPadnos> bbl
[22:40:12] <Jymmmm> NAS RAID
[22:40:14] <xemet> http://www.wreckedexotics.com/newphotos/exotics/
[22:40:58] <Skullworks> I used to solder only the wire on the ring side of the crimp
[22:41:22] <Skullworks> try not to let it wick up past the crimp
[22:41:42] <Skullworks> to get the best of both worlds
[22:43:35] <fenn> they should put some goldfish inside those wheels
[22:44:09] <alex_joni> ha..
http://www.junosora.com/wp/tigerscrane/2006/12/19/a-motorcycle-that-can-tow-a-car/
[22:44:49] <alex_joni> fenn: poor goldfish.. doing 90 on the freeway
[22:46:44] <Skullworks> Alex: those tow bikes better have additional brakes in that towing attachement...
[22:51:52] <Jymmmm> alex_joni: I uploaded this just for you....
http://farm1.static.flickr.com/139/394582911_56f5e93028_o.jpg
[22:56:53] <alex_joni> Jymmmm: hah
[22:58:04] <Skullworks> Ford on top!
[23:09:36] <Jymmmm> I'm thinking of buying one of these...
http://www.atacom.com/program/print_html_new.cgi?&USER_ID=www&cart_id=1369934_69_226_27_69&Item_code=NASX_ATAC_NA_00
[23:10:27] <fenn> why?
[23:10:38] <Jymmmm> 1.5TB RAID5
[23:10:55] <fenn> but.. why do you need 1.5TB raid?
[23:11:26] <Jymmmm> Ah, media jukebox.... I already finished making the TVPC w/ IR kybd/mouse
[23:11:41] <fenn> oh, a media jukebox..
[23:11:48] <fenn> how silly of me
[23:11:54] <skunkworks> we have filled up a .5TB server at work with art files. - They need them all - or so they say.
[23:11:55] <Skullworks> * Skullworks is old school - all u160LVD SCSI raids.
[23:11:56] <Jymmmm> mass storage on the backend.
[23:12:17] <Jymmmm> Skullworks But I can get 500GB SATA drives for $50/ea
[23:12:30] <Skullworks> Oh REALLY!
[23:12:39] <Jymmmm> Skullworks There's a catch
[23:12:47] <Skullworks> care to share the wealth?
[23:13:07] <Skullworks> (there always is...)
[23:13:55] <Jymmmm> Skullworks: Like I said, there's a catch... These drives have had a program called thrasher on them, so their integrity is questionable, no warranty, thus the RAID5 to CYA =)
[23:14:26] <Skullworks> and I thought I struck GOLD when I was able to buy the 74GB Cheetahs @$40
[23:14:59] <Skullworks> what was thrasher?
[23:15:19] <Skullworks> a MTBF test program?
[23:16:23] <Jymmmm> The company gets HDD's buy the pallet for testing purposes in their products. They do crash and burn testing.
[23:21:05] <Jymmmm> I found a SATA RAID5 card for $300 or this NAS RAID5 box for $500 that's self-enclosed and ready to go.
[23:22:09] <Skullworks> I'm tooo cheap
[23:23:11] <Jymmmm> Well, 500GB is ~$200 x 4 = $800 drives alone, or NAS box $500 + $200 HDD = $700 ready to go.
[23:23:20] <Skullworks> I'd just grab a spare PC case, chop off a molex connector and solder in 2 load resistors on the 5V line...
[23:23:52] <Skullworks> thats a quick and cheap drive enclosure
[23:24:24] <Jymmmm> Skullworks It's not JSUT a drive enclosure, it's a RAID5 nand NAS built in.
[23:24:25] <Skullworks> make some rear panel connector ports for the sata cables
[23:24:36] <Skullworks> OK
[23:24:58] <Skullworks> true - mine has to sit beside the host unit - not NAS
[23:25:06] <Jymmmm> You just plug it into the router and it's online.
[23:25:24] <Jymmmm> no computer to attach it to.
[23:25:29] <Skullworks> although my SCSI raid is 12ft away
[23:26:13] <Skullworks> I used NAS - it bogs terrible when doing vid editing
[23:26:39] <Jymmmm> This box also has USB ports in the back as well
[23:27:05] <Skullworks> my 64bit 39160 running parallel channels dumps data sooo fast
[23:27:40] <Skullworks> 800mb CD iso = 3 sec
[23:28:38] <Skullworks> * also getts his house heat by SCSI in winter.
[23:28:59] <Skullworks> Summer is... HOT
[23:30:28] <Skullworks> I don't fire up the extra RAIDs in summer unless I have to.
[23:32:08] <Skullworks> HARDWARE Question ?
[23:32:45] <Skullworks> what is a prefered Vid card that plays well with RT?
[23:32:57] <jepler> sh india
[23:32:59] <jepler> oops
[23:33:08] <alex_joni> Skullworks: most not onboard
[23:33:22] <alex_joni> but stay away from NVIDIA and ATI drivers
[23:33:50] <alex_joni> if you have a board like that use the open source driver
[23:34:56] <Skullworks> Current EMC2 box has a ATi Rage-128XL 8m agp
[23:35:47] <Skullworks> driver is whatever the Ubuntu install popped in during the Breezy install
[23:36:49] <Skullworks> all my hardware is old
[23:37:15] <Skullworks> I build junkyard monsters
[23:37:51] <alex_joni> then I think it should be just fine
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}